flink踩的坑
flink 窗口中watermark 第一个窗口的定义
- Timewindow类中初始窗口定义源码

timestamp为定义的时间 一般为event time
offset默认为o,可在定义窗口时传入
windowSize为滑动窗口步长
即源码中默认第一个窗口为
timestamp-timestamp%windowSize
阿里全托管flink集群选择
Per-Job集群(默认):作业之间资源隔离,每个作业都需要一个独立的JM,因此小任务JM的资源利用率较低。因此,适用于占用资源比较大或持续稳定运行的作业。
Session集群:多个作业可以复用相同的JM,可以提高JM资源利用率。因此适用于占用资源比较小或任务启停比较频繁的作业。
所以稳定且数据量多的dwd、dws可以适用Per-Job集群
较易更改且数据量较少的ads可以用Session
mysql cdc作为flink 源表是注意事项
- MySQL版本必须5.7 或8.0x
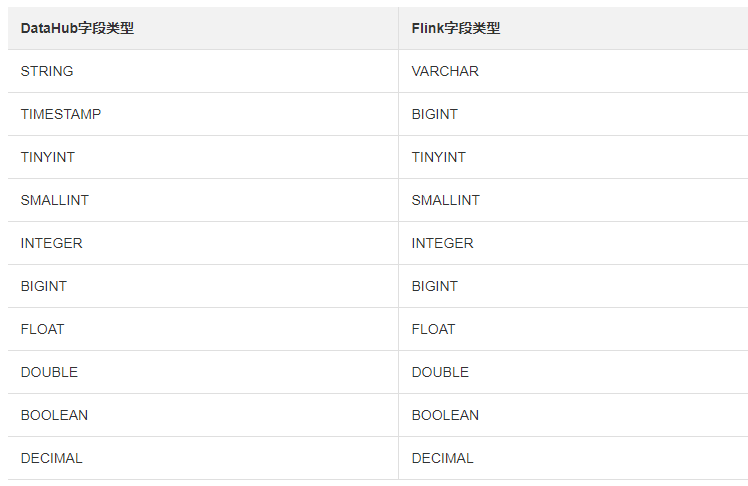
datahub与flink 字段类型对应关系
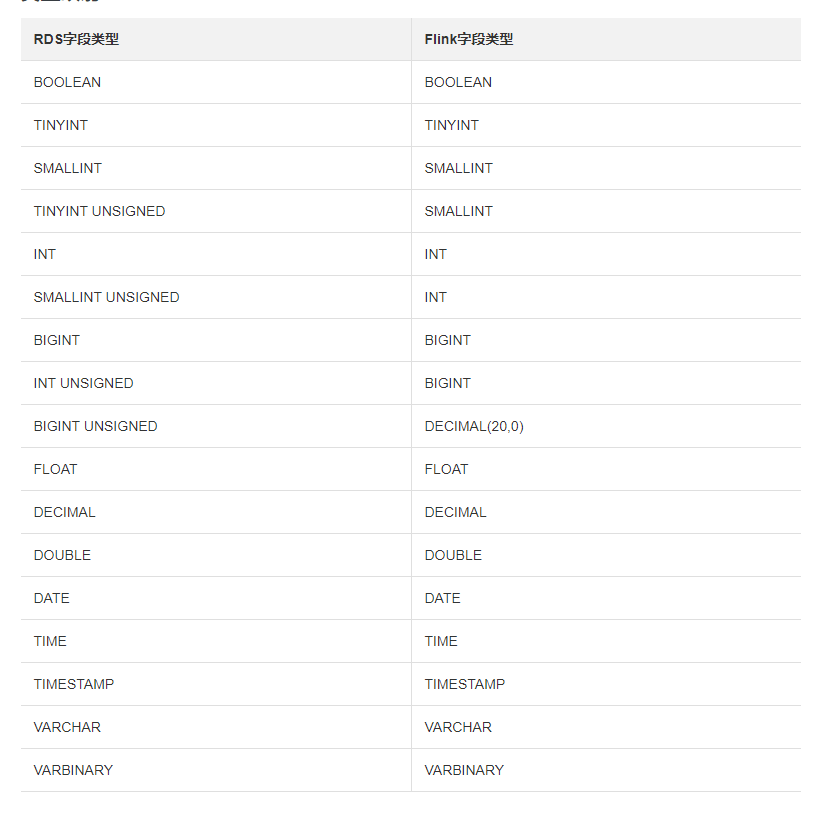
rds与flink字段类型对应关系
mysql的cdc源表和flink字段类型映射关系

flink 自定义函数
- 一对一:scalar function
- 一对多:table function
- 多对一:aggregate function
- 多对多:table aggregate function
flink jdbc connector
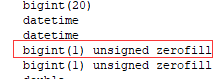 flink 无法读取bigint(1) unsigned zerofill类型
flink 无法读取bigint(1) unsigned zerofill类型
会报java.math.BigInteger cannot be cast to java.lang.Long错误
- 临时连接: JDBC连接器可以在临时连接中用作查找源。当前,仅支持同步查找模式。如果指定了查找缓存选项(connector.lookup.cache.max-rows和connector.lookup.cache.ttl),则必须全部指定它们。查找缓存用于通过首先查询缓存而不是将所有请求发送到远程数据库来提高临时连接JDBC连接器的性能。但是,如果来自缓存,则返回的值可能不是最新的。因此,这是吞吐量和正确性之间的平衡。
flink 全托管 自动调优设置
-
在作业代码中未配置作业并行度。 如果您使用了DataStream API或Table API接口编写作业,请确认作业代码中未配置作业并行度,否则自动调优将无法调整作业资源。

-
在界面和代码中未配置Task Manager数量。 如果在界面或代码中配置了Task Manager数量,自动调优将无法正常运行。
-
在YAML配置文件中未配置taskmanager.numberOfTaskSlots参数。
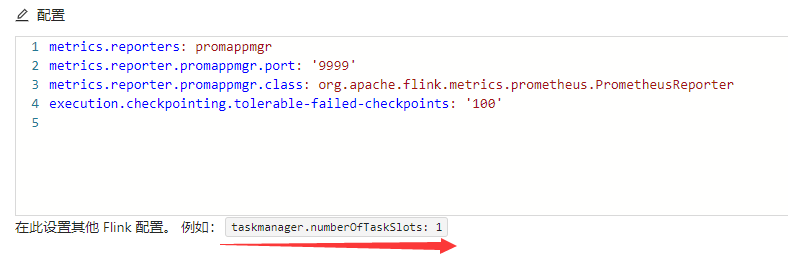
-
升级策略未配置为None。 如果升级策略配置为None,则修改作业配置后,系统不会自动重启作业,无法使自动调优配置生效。

flink 报错解决方案
在本地运行正常 但是打包上传到flink全托管环境下执行报错:
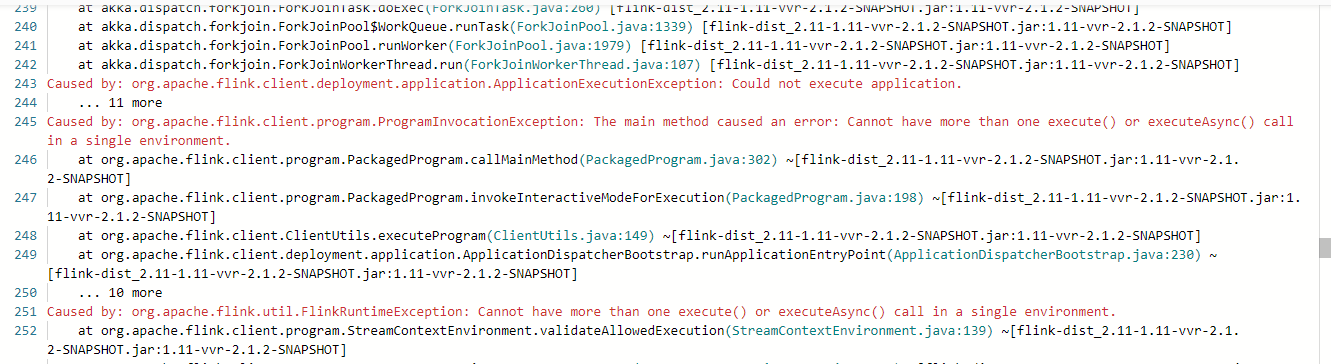
- 看源码和high-availability高可用相关 且在application mode下会报这错
- 在查看文档后发现当dataStream转成Table时要以tableEnv.execute() 代替env.execute()

- 更改后又报如下错误:
Exception in thread "main" java.lang.IllegalStateException: No operators defined in streaming topology. Cannot generate StreamGraph. at org.apache.flink.table.planner.utils.ExecutorUtils.generateStreamGraph(ExecutorUtils.java:47) at org.apache.flink.table.planner.delegation.StreamExecutor.createPipeline(StreamExecutor.java:47) at org.apache.flink.table.api.internal.TableEnvironmentImpl.execute(TableEnvironmentImpl.java:1197) at com.qihoo.flink.TableApiTest.main(TableApiTest.java:35)
- 原因:Flink TableEnvironment 使用 executeSql() 方法已经执行了sql语句,不需要再使用execute()方法。
运行execute()方法时,没有待执行的sql语句,因此会抛出此错误。
-
解决:在有executesql时 不需要env去执行execute,删除env.execute()
-
拓展:dataStream转换成table时要用 tableEnv去执行execute()