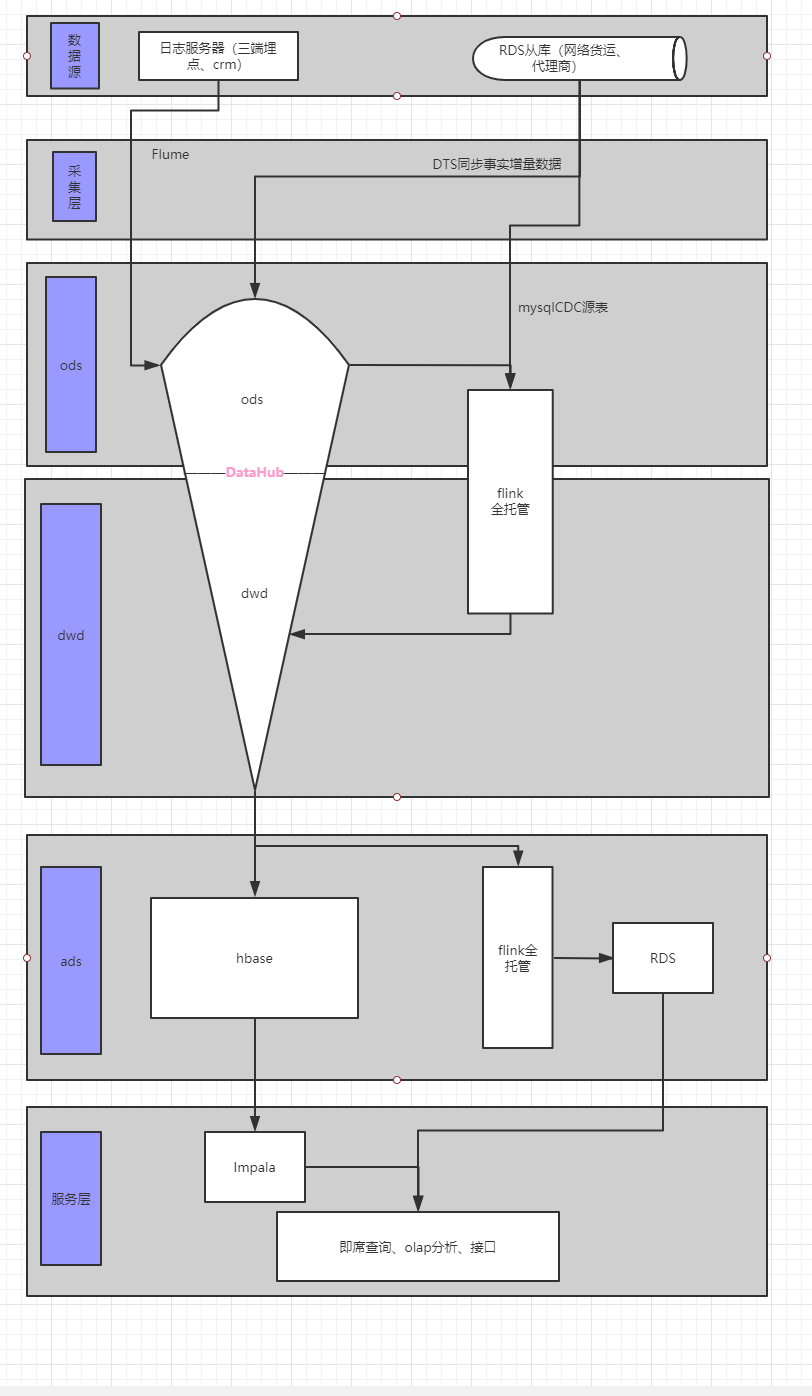
成丰实时数仓1.0
成丰实时数仓1.0
随着业务发展,财务局及地方单位监控加强,对外的可视化大屏展示、以及风控对实时的需求逐渐加大,dataworks最低5分钟的调度以满足不了现有业务发展,搭建实时数仓已成必然。
1.首先基于kappa架构的批流一体业界以逐渐成熟。开始的方案有考虑到kappa架构实现批流一体,但是成丰的离线数仓已经成熟,删除还是重构带来的工作量是巨大的,且要满足批流一体必须要实现全链路架构的全量持久化存储。首先datahub作为实时数仓的关键一环,其生命周期只有最大7天,这就没办法实现基本的多流相差7天以上的join,于是经过考虑,抛弃了这个架构。
2.于是采取了业界广泛使用且成熟的lambda架构,lambda架构的缺点也是无法避免的,实时离线的双系统冗余、一个指标实时离线各一套代码,开发周期加长。优点也就不言而喻,稳定成熟的架构方案,即使实时任务意外down掉,也保证数据不会异常丢失。
3.flink11引入了mysqlCDC源表,其中 lookup.cache.max-rows和lookup.cache.ttl分布设置最大缓存行数及超时时间,确定数据的效率和准确度的权重。缺点很明显当维表是order_common时,其需要在内存中存储百万条数据,这对于目前flink全托管10CU环境来说是开销是比较大的。
4.当我们完成对dwd层拉宽后,往hbasesink的时候发现本地环境执行正常,打包至flink全托管环境,报请求超时域名找不到等错误。后来想到,flink是北京2上的集群,而hbase配置的主从集群所在的ecs服务器在华北3张家口节点,这通过阿里云vpc是访问不到的。这必须通过公网访问,而4台服务器中只有hmater所在的节点cfhy4上开通了公网,但是我们的hbase是主从配置,通过zk协调服务管理元数据,hbase的读写会向zk寻求数据所在的region的meta表,在服务器上是配了域名映射,因此没开通公网的1、2节点访问就会报错。这就是说必须所有的从节点都必须开通公网,但是公网的带宽流量是比较贵的,因此为每台从节点配置公网是比较浪费的,这也只能期望阿里云能尽快开通flink张家口的节点。