flink sql source 源码解析
flink sql source 源码解析
先从一个简单的demo开始说起:
public class KafkaSourceDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
env.setParallelism(1);
EnvironmentSettings settings = EnvironmentSettings
.newInstance()
.useBlinkPlanner()
.inStreamingMode().build();
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env, settings);
tEnv.executeSql(
"CREATE TABLE source (\n"
+ " `name` STRING,\n"
+ " `city` STRING\n"
+ ") WITH (\n"
+ " 'connector' = 'kafka',\n"
+ " 'topic' = 'topic',\n"
+ " 'properties.bootstrap.servers' = 'localhost:9092',\n"
+ " 'properties.group.id' = 'test',\n"
+ " 'format' = 'json'\n"
+ ")"
);
Table t = tEnv.sqlQuery("SELECT * FROM source");
tEnv.toAppendStream(t, Row.class).print();
env.execute();
}
}
通过上面这段 sql 映射出的 transformations 中发现,其实 flink 中最关键变量:
1.sql source connector 是 FlinkKafkaConsumer
2.sql source format 是 JsonRowDataDeserializationSchema
所以我们就可以从下面这三个方向的问题去了解具体是怎么对应到具体的算子上的。
- sql source connector:用户指定了
connector = kafka,flink 是怎么自动映射到FlinkKafkaConsumer的? - sql source format:用户指定了
format = json,字段信息,flink 是怎么自动映射到JsonRowDataDeserializationSchema,以及字段解析的? - sql source properties:flink 是怎么自动将配置加载到
FlinkKafkaConsumer中的?
connector 怎样映射到具体算子
下图为官方原图介绍如何从元数据转换为运行时对象的处理过程。
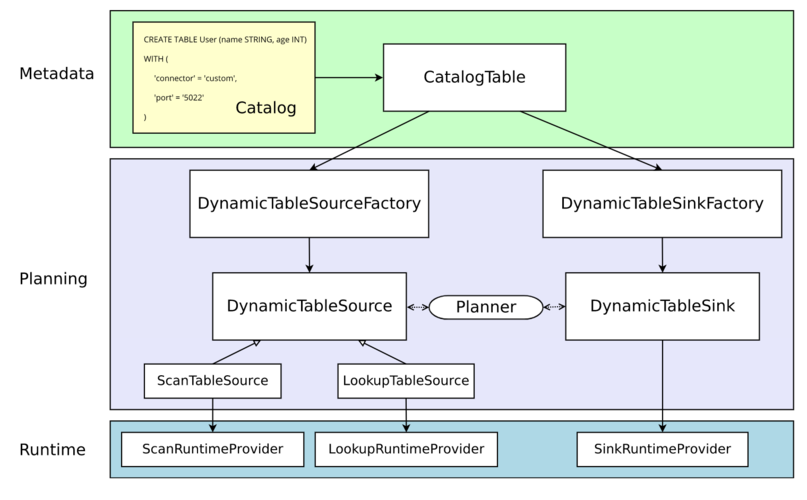
- Metadata
Table API 和 SQL 都是声明式 API,包括表的声明。执行 CREATE TABLE 语句会在目标 Catalog 中更新元数据。 动态表的元数据(通过 DDL 创建或由 Catalog 提供)表现为 CatalogTable 的实例。 对于大多数 Catalog 实现,不会为此类操作修改外部系统中的物理数据。Connector 特定的依赖也不必存在于 classpath 中。WITH 子句中声明的选项既不进行验证,也不进行其他解释。
- Planning
当涉及到处理执行计划和优化时,CatalogTable 需要解析为 DynamicTableSource(用于在 SELECT 查询中读取)和 DynamicTableSink(用于在 INSERT 语句中写入)。
DynamicTableSourceFactory 和 DynamicTableSinkFactory 提供逻辑将 CatalogTable 的元数据转换为 DynamicTableSource 和 DynamicTableSink 的实例。在大多数情况下,工厂的目的是验证 options(例如上图示例中的 'port'='5022')、配置编码/解码格式(如果需要)、创建 Table connector 的参数化实例。
默认情况下,DynamicTableSourceFactory 和 DynamicTableSinkFactory 的实例是使用 Java 的 SPI(Service Provider Interface)发现的。connector 选项(例如示例中的 'connector'='custom')必须对应有效的 factory 标识符。
尽管在类命名上可能不明显,但 DynamicTableSource 和 DynamicTableSink 也可以被视为有状态工厂,最终生成具体的运行时实现来读取/写入实际数据。Planner 使用 Source 和 Sink 实例找到最佳逻辑计划。
- Runtime
逻辑计划完成后,Planner 将获得运行时实现。运行时逻辑在 Flink 的 core connector 接口(如 InputFormat 或 SourceFunction )中实现。
这些接口按另一抽象级别划分为 ScanRuntimeProvider、LookupRuntimeProvider 和 SinkRuntimeProvider 的子类。
例如,OutputFormatProvider 和 SinkFunctionProvider 都是 Planner 可以处理的 SinkRuntimeProvider 的具体实例。
源码解析
-
进入CatalogSourceTable中
final DynamicTableSource tableSource = createDynamicTableSource(context, catalogTable);
这一行代码将 connector = kafka 映射到 FlinkKafkaConsumer,且将sql create source table 中信息传入catalogTable 变量
-
进入该方法
private DynamicTableSource createDynamicTableSource(
FlinkContext context, ResolvedCatalogTable catalogTable) {
final ReadableConfig config = context.getTableConfig().getConfiguration();
return FactoryUtil.createTableSource(
schemaTable.getCatalog(),
schemaTable.getTableIdentifier(),
catalogTable,
config,
Thread.currentThread().getContextClassLoader(),
schemaTable.isTemporary());
}
可以看到是使用了 FactoryUtil 创建了 DynamicTableSource。
-
进入
FactoryUtil.createTableSource
final DynamicTableSourceFactory factory = getDynamicTableFactory(DynamicTableSourceFactory.class, catalog, context);
return factory.createDynamicTableSource(context);
可以看到,就是最重要的两步操作。
- 先获取 kafka 工厂对象。
-
使用 kafka 工厂对象创建出 kafka source。
-
进入
FactoryUtil.getDynamicTableFactory
return discoverFactory(context.getClassLoader(), factoryClass, connectorOption);
final List<Factory> factories = discoverFactories(classLoader);
找到discoverFactories方法
private static List<Factory> discoverFactories(ClassLoader classLoader) {
try {
final List<Factory> result = new LinkedList<>();
ServiceLoader.load(Factory.class, classLoader).iterator().forEachRemaining(result::add);
return result;
} catch (ServiceConfigurationError e) {
LOG.error("Could not load service provider for factories.", e);
throw new TableException("Could not load service provider for factories.", e);
}
}
1.flink 是使用了 SPI 机制动态(SPI 机制天然插件化)的加载到了所有继承了 Factory 的工厂实例。
2.通过 connector = kafka + DynamicTableSourceFactory.class 的标识去过滤出 KafkaDynamicTableFactory。
-
返回到第三步中的createDynamicTableSource方法中去
protected KafkaDynamicSource createKafkaTableSource(
DataType physicalDataType,
@Nullable DecodingFormat<DeserializationSchema<RowData>> keyDecodingFormat,
DecodingFormat<DeserializationSchema<RowData>> valueDecodingFormat,
int[] keyProjection,
int[] valueProjection,
@Nullable String keyPrefix,
@Nullable List<String> topics,
@Nullable Pattern topicPattern,
Properties properties,
StartupMode startupMode,
Map<KafkaTopicPartition, Long> specificStartupOffsets,
long startupTimestampMillis) {
return new KafkaDynamicSource(
physicalDataType,
keyDecodingFormat,
valueDecodingFormat,
keyProjection,
valueProjection,
keyPrefix,
topics,
topicPattern,
properties,
startupMode,
specificStartupOffsets,
startupTimestampMillis,
false);
}
可以看到 KafkaDynamicTableFactory.createDynamicTableSource 中调用 KafkaDynamicTableFactory.createKafkaTableSource 来创建 KafkaDynamicSource。
基本上整个创建 Source 的流程就结束了。
总结
- MetaData:将 sql create source table 转化为实际的
CatalogTable、翻译为 RelNode - Planning:创建 RelNode 的过程中使用 SPI 将所有的 source(
DynamicTableSourceFactory)\sink(DynamicTableSinkFactory) 工厂动态加载,获取到 connector = kafka,然后从所有 source 工厂中过滤出名称为 kafka + 继承自DynamicTableSourceFactory.class的工厂类KafkaDynamicTableFactory,使用KafkaDynamicTableFactory创建出KafkaDynamicSource - Runtime:
KafkaDynamicSource创建出FlinkKafkaConsumer,负责 flink 程序实际运行。
format 怎样映射到具体 serde
源码解析
-
进入
KafkaDynamicTableFactory#createDynamicTableSource
final DecodingFormat<DeserializationSchema<RowData>> valueDecodingFormat = getValueDecodingFormat(helper);
通过该方法获取反序列化 schema 定义。
-
进入该方法
private static DecodingFormat<DeserializationSchema<RowData>> getValueDecodingFormat(
TableFactoryHelper helper) {
return helper.discoverOptionalDecodingFormat(
DeserializationFormatFactory.class, FactoryUtil.FORMAT)
.orElseGet(
() ->
helper.discoverDecodingFormat(
DeserializationFormatFactory.class, VALUE_FORMAT));
}
从反序列化工厂中获取到对应的反序列化schema
public <I, F extends DecodingFormatFactory<I>>
Optional<DecodingFormat<I>> discoverOptionalDecodingFormat(
Class<F> formatFactoryClass, ConfigOption<String> formatOption) {
return discoverOptionalFormatFactory(formatFactoryClass, formatOption)
.map(
formatFactory -> {
String formatPrefix = formatPrefix(formatFactory, formatOption);
try {
return formatFactory.createDecodingFormat(
context, projectOptions(formatPrefix));
} catch (Throwable t) {
throw new ValidationException(
String.format(
"Error creating scan format '%s' in option space '%s'.",
formatFactory.factoryIdentifier(),
formatPrefix),
t);
}
});
}
- 从format工厂获取到json format factory
- 从json format factory 创建反序列化schema
private <F extends Factory> Optional<F> discoverOptionalFormatFactory(
Class<F> formatFactoryClass, ConfigOption<String> formatOption) {
final String identifier = allOptions.get(formatOption);
if (identifier == null) {
return Optional.empty();
}
final F factory =
discoverFactory(context.getClassLoader(), formatFactoryClass, identifier);
String formatPrefix = formatPrefix(factory, formatOption);
// log all used options of other factories
consumedOptionKeys.addAll(
factory.requiredOptions().stream()
.map(ConfigOption::key)
.map(k -> formatPrefix + k)
.collect(Collectors.toSet()));
consumedOptionKeys.addAll(
factory.optionalOptions().stream()
.map(ConfigOption::key)
.map(k -> formatPrefix + k)
.collect(Collectors.toSet()));
return Optional.of(factory);
}
-
sql 中format = json 标识
-
flink 是使用了 SPI 机制动态(SPI 机制天然插件化)的加载到了所有继承了
Factory的 format 工厂实例。 -
通过 format = json 的标识并且继承自
DeserializationFormatFactory.class去过滤出JsonFormatFactory。
总结
- MetaData:和 connector 都一样
- Planning:format 是在创建 RelNode 的过程中,使用
KafkaDynamicTableFactory创建出KafkaDynamicSource时,通过 SPI 去动态过滤出 format = json 并且继承自DeserializationFormatFactory.class的 format 工厂类JsonFormatFactory。 - Runtime:
KafkaDynamicSource创建出FlinkKafkaConsumer时,实例化 serde 即JsonRowDataDeserializationSchema,负责 flink 程序实际运行时的反序列化。
其他配置属性怎么加载?
在 KafkaDynamicTableFactory 创建 KafkaDynamicTable 的过程中初始化。
源码解析
KafkaDynamicTableFactory #createDynamicTableSource
// add topic-partition discovery
properties.setProperty(
FlinkKafkaConsumerBase.KEY_PARTITION_DISCOVERY_INTERVAL_MILLIS,
String.valueOf(
tableOptions
.getOptional(SCAN_TOPIC_PARTITION_DISCOVERY)
.map(Duration::toMillis)
.orElse(FlinkKafkaConsumerBase.PARTITION_DISCOVERY_DISABLED)));