flink排错调优
flink排错调优
akka超时
- 错误日志:
org.apache.flink.util.FlinkException: An OperatorEvent from an OperatorCoordinator to a task was lost. Triggering task failover to ensure consistency. Event: 'SourceEventWrapper[com.ververica.cdc.connectors.mysql.source.events.FinishedSnapshotSplitsRequestEvent@6961b00f]', targetTask: Source: TableSourceScan(table=[[vvp, default, ex_order_pending_history_spot_msq]], fields=[id, user_id, account_type, pair, client_oid, coin_id, coin_symbol, currency_id, currency_symbol, order_side, order_type, order_otype, price, amount, money, deal_price, deal_amount, deal_money, deal_count, fee, pay_bix, status, reason, order_from, createdAt, updatedAt], hints=[[[OPTIONS options:{server-id=5100-5104}]]]) -> Calc(select=[id, user_id, account_type, pair, client_oid, coin_id, coin_symbol, currency_id, currency_symbol, order_side, order_type, order_otype, price, amount, money, deal_price, deal_amount, deal_money, deal_count, fee, pay_bix, status, reason, order_from, createdAt, updatedAt], where=[(status >= 3)]) -> NotNullEnforcer(fields=[id, user_id, pair, coin_symbol, currency_symbol]) -> Sink: Sink(table=[vvp.default.ex_order_pending_history_spot_holo], fields=[id, user_id, account_type, pair, client_oid, coin_id, coin_symbol, currency_id, currency_symbol, order_side, order_type, order_otype, price, amount, money, deal_price, deal_amount, deal_money, deal_count, fee, pay_bix, status, reason, order_from, createdAt, updatedAt]) (1/4) - execution #2
at org.apache.flink.runtime.operators.coordination.SubtaskGatewayImpl.lambda$null$0(SubtaskGatewayImpl.java:90)
at org.apache.flink.runtime.util.Runnables.lambda$withUncaughtExceptionHandler$0(Runnables.java:47)
at org.apache.flink.runtime.util.Runnables.assertNoException(Runnables.java:31)
at org.apache.flink.runtime.operators.coordination.SubtaskGatewayImpl.lambda$sendEvent$1(SubtaskGatewayImpl.java:88)
at java.util.concurrent.CompletableFuture.uniWhenComplete(CompletableFuture.java:760)
at java.util.concurrent.CompletableFuture$UniWhenComplete.tryFire(CompletableFuture.java:736)
at java.util.concurrent.CompletableFuture$Completion.run(CompletableFuture.java:442)
at org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleRunAsync(AkkaRpcActor.java:440)
at org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleRpcMessage(AkkaRpcActor.java:208)
at org.apache.flink.runtime.rpc.akka.FencedAkkaRpcActor.handleRpcMessage(FencedAkkaRpcActor.java:77)
at org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleMessage(AkkaRpcActor.java:158)
at akka.japi.pf.UnitCaseStatement.apply(CaseStatements.scala:26)
at akka.japi.pf.UnitCaseStatement.apply(CaseStatements.scala:21)
at scala.PartialFunction$class.applyOrElse(PartialFunction.scala:123)
at akka.japi.pf.UnitCaseStatement.applyOrElse(CaseStatements.scala:21)
at scala.PartialFunction$OrElse.applyOrElse(PartialFunction.scala:170)
at scala.PartialFunction$OrElse.applyOrElse(PartialFunction.scala:171)
at scala.PartialFunction$OrElse.applyOrElse(PartialFunction.scala:171)
at akka.actor.Actor$class.aroundReceive(Actor.scala:517)
at akka.actor.AbstractActor.aroundReceive(AbstractActor.scala:225)
at akka.actor.ActorCell.receiveMessage(ActorCell.scala:592)
at akka.actor.ActorCell.invoke(ActorCell.scala:561)
at akka.dispatch.Mailbox.processMailbox(Mailbox.scala:258)
at akka.dispatch.Mailbox.run(Mailbox.scala:225)
at akka.dispatch.Mailbox.exec(Mailbox.scala:235)
at akka.dispatch.forkjoin.ForkJoinTask.doExec(ForkJoinTask.java:260)
at akka.dispatch.forkjoin.ForkJoinPool$WorkQueue.runTask(ForkJoinPool.java:1339)
at akka.dispatch.forkjoin.ForkJoinPool.runWorker(ForkJoinPool.java:1979)
at akka.dispatch.forkjoin.ForkJoinWorkerThread.run(ForkJoinWorkerThread.java:107)
Caused by: java.util.concurrent.TimeoutException: Invocation of public abstract java.util.concurrent.CompletableFuture org.apache.flink.runtime.taskexecutor.TaskExecutorGateway.sendOperatorEventToTask(org.apache.flink.runtime.executiongraph.ExecutionAttemptID,org.apache.flink.runtime.jobgraph.OperatorID,org.apache.flink.util.SerializedValue) timed out.
at org.apache.flink.runtime.jobmaster.RpcTaskManagerGateway.sendOperatorEventToTask(RpcTaskManagerGateway.java:120)
at org.apache.flink.runtime.executiongraph.Execution.sendOperatorEvent(Execution.java:939)
at org.apache.flink.runtime.operators.coordination.ExecutionSubtaskAccess.lambda$createEventSendAction$1(ExecutionSubtaskAccess.java:67)
at org.apache.flink.runtime.operators.coordination.OperatorEventValve.callSendAction(OperatorEventValve.java:180)
at org.apache.flink.runtime.operators.coordination.OperatorEventValve.sendEvent(OperatorEventValve.java:94)
at org.apache.flink.runtime.operators.coordination.SubtaskGatewayImpl.lambda$sendEvent$2(SubtaskGatewayImpl.java:98)
... 22 more
Caused by: akka.pattern.AskTimeoutException: Ask timed out on [Actor[akka.tcp://flink@192.168.4.56:6122/user/rpc/taskmanager_0#1092173364]] after [10000 ms]. Message of type [org.apache.flink.runtime.rpc.messages.RemoteRpcInvocation]. A typical reason for `AskTimeoutException` is that the recipient actor didn't send a reply.
at akka.pattern.PromiseActorRef$$anonfun$2.apply(AskSupport.scala:635)
at akka.pattern.PromiseActorRef$$anonfun$2.apply(AskSupport.scala:635)
at akka.pattern.PromiseActorRef$$anonfun$1.apply$mcV$sp(AskSupport.scala:648)
at akka.actor.Scheduler$$anon$4.run(Scheduler.scala:205)
at scala.concurrent.Future$InternalCallbackExecutor$.unbatchedExecute(Future.scala:601)
at scala.concurrent.BatchingExecutor$class.execute(BatchingExecutor.scala:109)
at scala.concurrent.Future$InternalCallbackExecutor$.execute(Future.scala:599)
at akka.actor.LightArrayRevolverScheduler$TaskHolder.executeTask(LightArrayRevolverScheduler.scala:328)
at akka.actor.LightArrayRevolverScheduler$$anon$4.executeBucket$1(LightArrayRevolverScheduler.scala:279)
at akka.actor.LightArrayRevolverScheduler$$anon$4.nextTick(LightArrayRevolverScheduler.scala:283)
at akka.actor.LightArrayRevolverScheduler$$anon$4.run(LightArrayRevolverScheduler.scala:235)
at java.lang.Thread.run(Thread.java:834)
- 原因:tm通信超时,akka的通信超时时间默认是10s
- 解决:增大akka的超时时间,需要配置参数:
akka.ask.timeout: 600s
制作checkpoint超时
- 错误日志:
org.apache.flink.util.FlinkRuntimeException: Exceeded checkpoint tolerable failure threshold.
at org.apache.flink.runtime.checkpoint.CheckpointFailureManager.handleCheckpointException(CheckpointFailureManager.java:98)
at org.apache.flink.runtime.checkpoint.CheckpointFailureManager.handleJobLevelCheckpointException(CheckpointFailureManager.java:67)
at org.apache.flink.runtime.checkpoint.CheckpointCoordinator.abortPendingCheckpoint(CheckpointCoordinator.java:2021)
at org.apache.flink.runtime.checkpoint.CheckpointCoordinator.abortPendingCheckpoint(CheckpointCoordinator.java:1993)
at org.apache.flink.runtime.checkpoint.CheckpointCoordinator.access$600(CheckpointCoordinator.java:97)
at org.apache.flink.runtime.checkpoint.CheckpointCoordinator$CheckpointCanceller.run(CheckpointCoordinator.java:2077)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$201(ScheduledThreadPoolExecutor.java:186)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:299)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1147)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:622)
at java.lang.Thread.run(Thread.java:834)
- 原因:flink在制作cp是超时了。
- 解决:增大cp的超时时间,添加配置
execution.checkpointing.timeout: 1800 s
execution.checkpointing.tolerable-failed-checkpoints: '3'
第一个参数是增大制作checkpoint的超时时间。
第二个是增大允许Checkpoint失败的次数,默认是0不允许,失败就报错。
taskmanager心跳超时
- 错误日志:
java.util.concurrent.TimeoutException: Heartbeat of TaskManager with id job-08b92e3f-8246-491c-b0bf-33792e627884-taskmanager-1-4 timed out.
at org.apache.flink.runtime.jobmaster.JobMaster$TaskManagerHeartbeatListener.notifyHeartbeatTimeout(JobMaster.java:1335) ~[flink-dist_2.11-1.13-vvr-4.0.11-3-SNAPSHOT.jar:1.13-vvr-4.0.11-3-SNAPSHOT]
at org.apache.flink.runtime.heartbeat.HeartbeatMonitorImpl.run(HeartbeatMonitorImpl.java:111) ~[flink-dist_2.11-1.13-vvr-4.0.11-3-SNAPSHOT.jar:1.13-vvr-4.0.11-3-SNAPSHOT]
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) ~[?:1.8.0_102]
at java.util.concurrent.FutureTask.run(FutureTask.java:266) ~[?:1.8.0_102]
at org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleRunAsync(AkkaRpcActor.java:440) ~[flink-dist_2.11-1.13-vvr-4.0.11-3-SNAPSHOT.jar:1.13-vvr-4.0.11-3-SNAPSHOT]
at org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleRpcMessage(AkkaRpcActor.java:208) ~[flink-dist_2.11-1.13-vvr-4.0.11-3-SNAPSHOT.jar:1.13-vvr-4.0.11-3-SNAPSHOT]
at org.apache.flink.runtime.rpc.akka.FencedAkkaRpcActor.handleRpcMessage(FencedAkkaRpcActor.java:77) ~[flink-dist_2.11-1.13-vvr-4.0.11-3-SNAPSHOT.jar:1.13-vvr-4.0.11-3-SNAPSHOT]
at org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleMessage(AkkaRpcActor.java:158) ~[flink-dist_2.11-1.13-vvr-4.0.11-3-SNAPSHOT.jar:1.13-vvr-4.0.11-3-SNAPSHOT]
at akka.japi.pf.UnitCaseStatement.apply(CaseStatements.scala:26) [flink-dist_2.11-1.13-vvr-4.0.11-3-SNAPSHOT.jar:1.13-vvr-4.0.11-3-SNAPSHOT]
at akka.japi.pf.UnitCaseStatement.apply(CaseStatements.scala:21) [flink-dist_2.11-1.13-vvr-4.0.11-3-SNAPSHOT.jar:1.13-vvr-4.0.11-3-SNAPSHOT]
at scala.PartialFunction$class.applyOrElse(PartialFunction.scala:123) [flink-dist_2.11-1.13-vvr-4.0.11-3-SNAPSHOT.jar:1.13-vvr-4.0.11-3-SNAPSHOT]
at akka.japi.pf.UnitCaseStatement.applyOrElse(CaseStatements.scala:21) [flink-dist_2.11-1.13-vvr-4.0.11-3-SNAPSHOT.jar:1.13-vvr-4.0.11-3-SNAPSHOT]
at scala.PartialFunction$OrElse.applyOrElse(PartialFunction.scala:170) [flink-dist_2.11-1.13-vvr-4.0.11-3-SNAPSHOT.jar:1.13-vvr-4.0.11-3-SNAPSHOT]
at scala.PartialFunction$OrElse.applyOrElse(PartialFunction.scala:171) [flink-dist_2.11-1.13-vvr-4.0.11-3-SNAPSHOT.jar:1.13-vvr-4.0.11-3-SNAPSHOT]
at scala.PartialFunction$OrElse.applyOrElse(PartialFunction.scala:171) [flink-dist_2.11-1.13-vvr-4.0.11-3-SNAPSHOT.jar:1.13-vvr-4.0.11-3-SNAPSHOT]
at akka.actor.Actor$class.aroundReceive(Actor.scala:517) [flink-dist_2.11-1.13-vvr-4.0.11-3-SNAPSHOT.jar:1.13-vvr-4.0.11-3-SNAPSHOT]
at akka.actor.AbstractActor.aroundReceive(AbstractActor.scala:225) [flink-dist_2.11-1.13-vvr-4.0.11-3-SNAPSHOT.jar:1.13-vvr-4.0.11-3-SNAPSHOT]
at akka.actor.ActorCell.receiveMessage(ActorCell.scala:592) [flink-dist_2.11-1.13-vvr-4.0.11-3-SNAPSHOT.jar:1.13-vvr-4.0.11-3-SNAPSHOT]
at akka.actor.ActorCell.invoke(ActorCell.scala:561) [flink-dist_2.11-1.13-vvr-4.0.11-3-SNAPSHOT.jar:1.13-vvr-4.0.11-3-SNAPSHOT]
at akka.dispatch.Mailbox.processMailbox(Mailbox.scala:258) [flink-dist_2.11-1.13-vvr-4.0.11-3-SNAPSHOT.jar:1.13-vvr-4.0.11-3-SNAPSHOT]
at akka.dispatch.Mailbox.run(Mailbox.scala:225) [flink-dist_2.11-1.13-vvr-4.0.11-3-SNAPSHOT.jar:1.13-vvr-4.0.11-3-SNAPSHOT]
at akka.dispatch.Mailbox.exec(Mailbox.scala:235) [flink-dist_2.11-1.13-vvr-4.0.11-3-SNAPSHOT.jar:1.13-vvr-4.0.11-3-SNAPSHOT]
at akka.dispatch.forkjoin.ForkJoinTask.doExec(ForkJoinTask.java:260) [flink-dist_2.11-1.13-vvr-4.0.11-3-SNAPSHOT.jar:1.13-vvr-4.0.11-3-SNAPSHOT]
at akka.dispatch.forkjoin.ForkJoinPool$WorkQueue.runTask(ForkJoinPool.java:1339) [flink-dist_2.11-1.13-vvr-4.0.11-3-SNAPSHOT.jar:1.13-vvr-4.0.11-3-SNAPSHOT]
at akka.dispatch.forkjoin.ForkJoinPool.runWorker(ForkJoinPool.java:1979) [flink-dist_2.11-1.13-vvr-4.0.11-3-SNAPSHOT.jar:1.13-vvr-4.0.11-3-SNAPSHOT]
at akka.dispatch.forkjoin.ForkJoinWorkerThread.run(ForkJoinWorkerThread.java:107) [flink-dist_2.11-1.13-vvr-4.0.11-3-SNAPSHOT.jar:1.13-vvr-4.0.11-3-SNAPSHOT]
- 原因:jm接受tm的心跳超时。
- 解决:增大心跳超时时间,
heartbeat.timeout: '180000'默认50000即50秒。
排查job反压情况以及解决思路
flink默认是开启算子链的,导致当个cdc任务只有一个vertex。由于Flink的特性,在最后一个Vertex的输出上没有设置网络Buffer(直接写出到下游存储),当作业仅存在一个(或最后一个)Vertex时,反压检测机制失效。所以对单一的vertex就行拆分,通过添加参数pipeline.operator-chaining: 'false'关闭算子链。
cdc任务默认开启算子链时:

关闭算子链后:
查看vertex的反压情况:
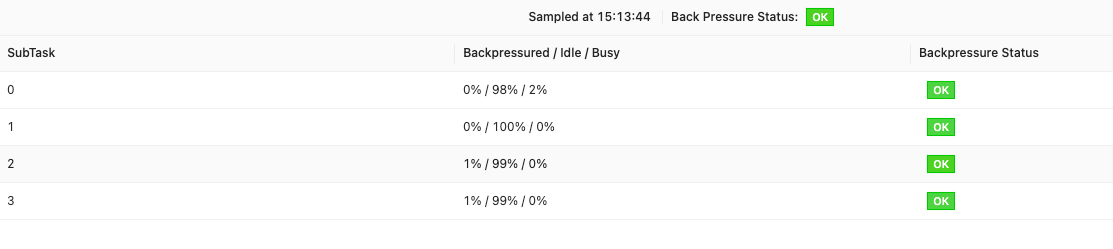
排查思路:
示意图中Vertex的颜色为绿色表示通过以上的检测显示不存在反压,红色表示存在反压。
- 存在多个Vertex,倒数第2个Vertex经检测存在反压
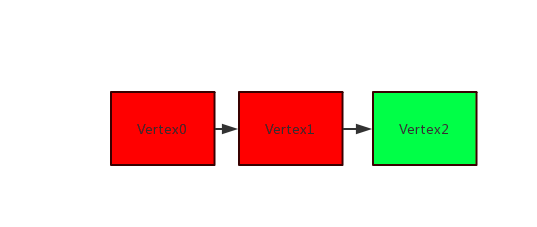
该场景表示:Vertex1被反压,性能瓶颈点在Vertex2。此时,可以通过查看Vertex2中的Operator组的名称进行判断:
- 若只涉及写出下游存储的操作,则可能是写出速度较慢所导致。建议增加Vertex2的并发数,或者配置对应结果表(Sink)的
batchsize参数。 -
若涉及到除写出下游存储外的其他操作,需要将其他操作对应的Operator拆分后再进一步判断。
- 存在多个Vertex,非倒数第2个Vertex经检测存在反压
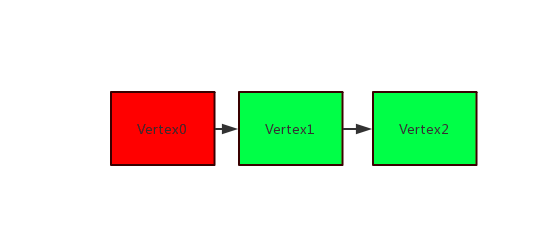
该场景表示:Vertex0被反压,性能瓶颈点在Vertex1。此时,可以通过查看Vertex1中的Operator组的名称来判断具体的操作。常见的操作和对应的优化方法如下:
- GROUP BY操作:可以考虑增加并发或设置
miniBatch参数优化状态(State)的操作。 - 维表JOIN操作:可以考虑增加并发数或者设置维表的Cache策略,具体请参见对应维表文档。
-
UDX操作:可以考虑增加并发数或者优化对应的UDX代码。
- 存在多个Vertex,所有Vertex经检测不存在反压
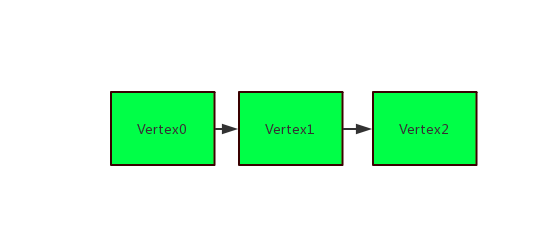
该场景表示:可能的性能瓶颈点在Vertex0,可以通过查看Vertex0中的Operator组的名称判断具体的操作。
- 存在多个Vertex,其中1个Vertex经检测存在反压,但其后续的多个并行Vertex经检测不存在反压
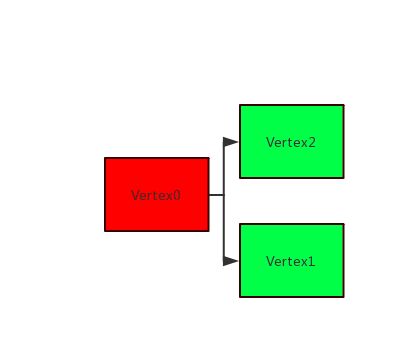
该场景表示:Vertex0被反压,但是无法直接判断性能瓶颈点是Vertex1还是Vertex2。您可以通过Vertex1和Vertex2的IN_Q指标做初步判断,如果对应的IN_Q长时间为100%,则此节点极可能存在性能瓶颈点。若需要进一步确认,则需将此节点拆分后进行进一步判断。
查看job的数据延迟
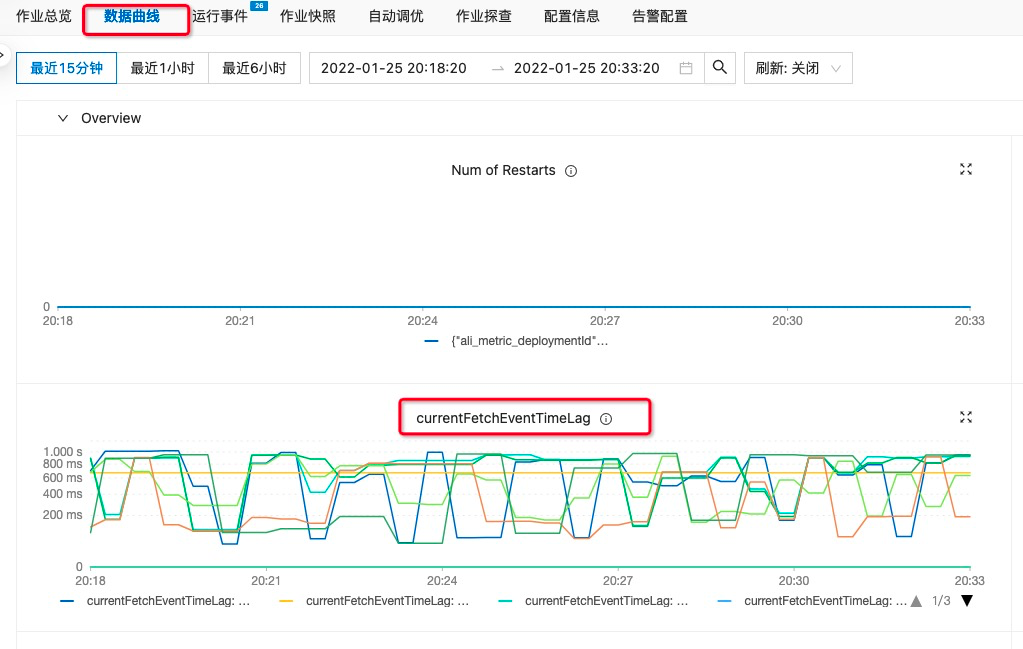
cdc任务数据延迟计算规则:当前时间减去数据库变更数据的时间
oom问题排查
- 开启gc日志
env.java.opts: >-
-XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:/flink/log/gc.log
-XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=2 -XX:GCLogFileSize=50M
- 查看gc日志
- 异常:
2022-01-25T21:59:25.642+0800: 510.214: [GC (Allocation Failure) 2022-01-25T21:59:25.642+0800: 510.214: [ParNew: 76671K->8512K(76672K), 0.1891483 secs] 3073442K->3034303K(3530432K), 0.1894421 secs] [Times: user=0.18 sys=0.01, real=0.19 secs]
新生代一直失败,减小老年代和新生代和的大小,参数如下,在重启任务
env.java.opts="-XX:NewRatio=2"
- 异常:
2022-11-07 08:03:49,540 WARN org.jboss.netty.channel.socket.nio.AbstractNioSelector [] - Unexpected exception in the selector loop.
java.lang.OutOfMemoryError: Direct buffer memory
at java.nio.Bits.reserveMemory(Bits.java:706) ~[?:1.8.0_102]
at java.nio.DirectByteBuffer.<init>(DirectByteBuffer.java:123) ~[?:1.8.0_102]
at java.nio.ByteBuffer.allocateDirect(ByteBuffer.java:311) ~[?:1.8.0_102]
at org.jboss.netty.channel.socket.nio.SocketReceiveBufferAllocator.newBuffer(SocketReceiveBufferAllocator.java:64) ~[flink-rpc-akka_07b11365-31f5-4a6e-bdd0-3b611bcbf3cf.jar:1.15-vvr-6.0.2-3-SNAPSHOT]
at org.jboss.netty.channel.socket.nio.SocketReceiveBufferAllocator.get(SocketReceiveBufferAllocator.java:44) ~[flink-rpc-akka_07b11365-31f5-4a6e-bdd0-3b611bcbf3cf.jar:1.15-vvr-6.0.2-3-SNAPSHOT]
at org.jboss.netty.channel.socket.nio.NioWorker.read(NioWorker.java:62) ~[flink-rpc-akka_07b11365-31f5-4a6e-bdd0-3b611bcbf3cf.jar:1.15-vvr-6.0.2-3-SNAPSHOT]
at org.jboss.netty.channel.socket.nio.AbstractNioWorker.process(AbstractNioWorker.java:108) ~[flink-rpc-akka_07b11365-31f5-4a6e-bdd0-3b611bcbf3cf.jar:1.15-vvr-6.0.2-3-SNAPSHOT]
at org.jboss.netty.channel.socket.nio.AbstractNioSelector.run(AbstractNioSelector.java:337) [flink-rpc-akka_07b11365-31f5-4a6e-bdd0-3b611bcbf3cf.jar:1.15-vvr-6.0.2-3-SNAPSHOT]
at org.jboss.netty.channel.socket.nio.AbstractNioWorker.run(AbstractNioWorker.java:89) [flink-rpc-akka_07b11365-31f5-4a6e-bdd0-3b611bcbf3cf.jar:1.15-vvr-6.0.2-3-SNAPSHOT]
at org.jboss.netty.channel.socket.nio.NioWorker.run(NioWorker.java:178) [flink-rpc-akka_07b11365-31f5-4a6e-bdd0-3b611bcbf3cf.jar:1.15-vvr-6.0.2-3-SNAPSHOT]
at org.jboss.netty.util.ThreadRenamingRunnable.run(ThreadRenamingRunnable.java:108) [flink-rpc-akka_07b11365-31f5-4a6e-bdd0-3b611bcbf3cf.jar:1.15-vvr-6.0.2-3-SNAPSHOT]
at org.jboss.netty.util.internal.DeadLockProofWorker$1.run(DeadLockProofWorker.java:42) [flink-rpc-akka_07b11365-31f5-4a6e-bdd0-3b611bcbf3cf.jar:1.15-vvr-6.0.2-3-SNAPSHOT]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1147) [?:1.8.0_102]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:622) [?:1.8.0_102]
at java.lang.Thread.run(Thread.java:834) [?:1.8.0_102]
JVM直接内存太小或存在直接内存泄漏。Flink总内存包括JVM堆内内存和堆外内存,而堆外内存包括直接内存和本机内存。所以增大直接内存就行,相关参数有两个:
- jobmanager.memory.enable-jvm-direct-memory-limit
是否开启JobManager进程的JVM直接内存限制(-XX:MaxDirectMemorySize)。该限制将设置为“jobmanager.memory.off-heap.size”选项的值。
默认为false,无需调整。
- jobmanager.memory.off-heap
JobManager 的堆外内存大小。
默认128M,增大值即可
join查询
table.exec.state.ttl:指定将保留多长时间的空闲状态(即未更新的状态)单位毫秒
Versioned Table(版本表):基于变更日志的表,如upsert kafka、cdc(debezium、canal)
必须包含一个PRIMARY KEY和一个事件时间属性
- Regular Join
常规join,状态会无限扩大,通过设置table.exec.state.ttl避免,最终结果会一直变化
-
LeftAntiJoin 即not in,并发始终为1
-
Temporal join for Processing time
左表关联构建端最新版本的数据。
之前关联的结果不会发生改变
- Temporal join for event time
左表根据event time 关联构建端版本表中对应版本的数据。
之前关联的结果不会发生改变
- Interval Join
间隔join,会记录间隔窗口的状态,只有窗口内的结果会变更,为inner join。
- Lookup join
通过LRU Cache缓存外部系统数据。
lookup.cache.max-rows and lookup.cache.ttl 参数来启用。
Lookup join和 Processing Time Temporal join 的区别
两者都是取构建端最新的数据并且之前关联的结果都不会发生改变,那为什么flink提供处理时间临时连接,主要原因如下:
- Lookup join更昂贵——它需要查询外部数据库,并等待响应。虽然有缓存,但是可能会关联过期的数据。通过处理时间临时连接,可以确保使用最新的数据。
- Lookup join需要实现一个特殊的连接器。临时连接使用标准的流式连接器,更加通用。
##